Branching Strategy
What is A Branching Strategy?
A Branching Strategy is how a software development team uses a version control system (like git) to:
- write software code
- save that code, being able to access prior versions of it
- combine that code into a single 'codebase' (everyone's individual contributions being put together into one)
- deploy that code to customers, in the form of data, applications or websites.
The branching strategy that we use here at Entain Australia, in the React Native chapter, is called Trunk Based Development. We use git for our version control system.
What is Trunk Based Development?
To quote Paul Hammant, who wrote extensively on Trunk Based Development, it is:
A source-control branching model, where developers collaborate on code in a single branch called ‘trunk’ , resist any pressure to create other long-lived development branches by employing documented techniques. They therefore avoid merge hell, do not break the build, and live happily ever after. main or master, in Git nomenclature
The central benefit of Trunk Based Development is a reduction in the amount of branches a team has to track and deal with at any one time from start to deployment, and avoiding a lot of merge conflicts when several branches (such as those used in a Git Flow branching strategy) need to be merged back into each other.
Please note that "Branching Strategy", "source-control branching model", can be though of interchangeably here.
So let's break those down one by one, shall we?
Code [from] a single branch
We have one main branch in our code (that is the equivalent to master in many other projects).
Everyone branches off of main and creates a feature branch for them to work on some new feature, change, bug fix, or whatever it is they need to do. (e.g. feature/my-working-feature)
Once they are done writing code and making changes, and are ready to merge their branch back in to the rest of the codebase, they open a Merge Request (MR) and target the main branch directly.
That's it. You branch off of main, then merge back into main.
A note about the quote's own wording: Instead of working "in" a single branch, we are working "from" a single branch, because TBD specifies that smaller teams can actually simply make changes from and commit back into their main branch.
However, for any team at scale, creating a separate feature branch and then using code reviewing and merge requests is recommended, and much more sane - hence, why we do it. Just to clear up confusion from what you would initially read on the TBD website, and from reading that quote.
The main thing TBD focuses on as far as branches go is to use as few of them as possible, and don't let them exist for more than a couple of days max.
Fewer branches, that exist for shorter periods of time, is mainly wanted to avoid having a lot or really complicated merge conflicts. The more branches exist, and the longer they exist for while people work on them, the more likely is the code in each of those branches to be different - or divergent - meaning that once they need to be merged back, the same files might have multiple versions and it can take a lot of time, and sometimes even guessing which changes are to be kept. In rare occasions, changes might end up being lost in the merge, leading to unexpected code behavior that the team thought was implemented or fixed!
Yes, but what about releases and fixes for bugs in production?
Generally speaking, in TBD releases are done by creating a release/ branch off of the main branch. This release/ branch (e.g. release/10-5-0, following a Semantic Versioning numbering) is the version of code that our Quality Assurance (QA) team would then test.
If the QA team finds any bugs, the process for fixing the bugs will be generally the same, whether the features and changes in the latest release/ branch has already been shipped to customers or not.
For bugs found before the release/ is shipped, we create a new brain off of main, make our fixes, and then merge back into main through a Merge Request (MR). Once the MR is approved and the changes are merged to main, we then 'cherry-pick' the same changes into the release/ branch that has the bug. Doing things this way is called "downstream fixing", because we are making the fix into main first, and then copying those same changes "down" to the release/ branch using cherry-picking in git.
For a bug found after release/ has already shipped, a bug in production, the process is exactly the same, except that rather than cherry-picking into the already shipped release/ branch (e.g. release/10-5-0) we would create a new release/ branch off of the shipped one (e.g. release/10-5-1) incrementing it's patch version number, and cherry-picking the fix from main into that new, yet to be released branch, which can then in turn be shipped to customers to deploy those latest fixes.
Depending on whether the files where the bug has been detected have changed since the release/ branch was created will dictate some other details about the process.
You must read the following step by step practical guide on fixing and hot-fixing.
Branch by Abstraction (Resist long-lived development branches)
When working in Git Flow branching strategy projects, any sort of feature or change would be done on a dedicated feature branch until the feature or change is complete, and it is then merged back into the main development branch.
A problem can occur when that feature branch is "long lived", meaning that the work took quite some time to do (e.g. a couple of sprints or more), whereby the feature and main development branch existing apart for a long time and may result in their code diverging quite a bit. This can lead to a lot of merge conflicts when the feature or change is ready to be merged back in, especially if the work touches upon areas of active development.
The proposed solution in Trunk Based Development is to instead commit work in progress to the main branch, and do so safely by wrapping it with an abstraction (such as a feature flag) that outwardly behaves exactly like the existing code, but internally can be switched the execute the old code or the new, work in progress code. As far as the rest of the codebase is concerned, nothing has changed, and for the work in progress, it can continue in a more relaxed fashion.
To borrow from the Trunk Based Development website itself, imagine having to replace a wheel on a car, without removing the functionality of the original wheel. First you would mount a pseudo-wheel that has the original wheel attached to it. Slowly you start making and attaching the replacement wheel onto the pseudo wheel. At some point you will have both the original wheel and the replacement wheel on the pseudo wheel. At this point, you remove the original wheel, leaving only the replacement wheel attached to the pseudo-wheel. After you're satisfied everything is still working, you remove the pseudo-wheel, leaving only the replacement wheel. The car was able to move the whole time that you were working on replacing the wheel.
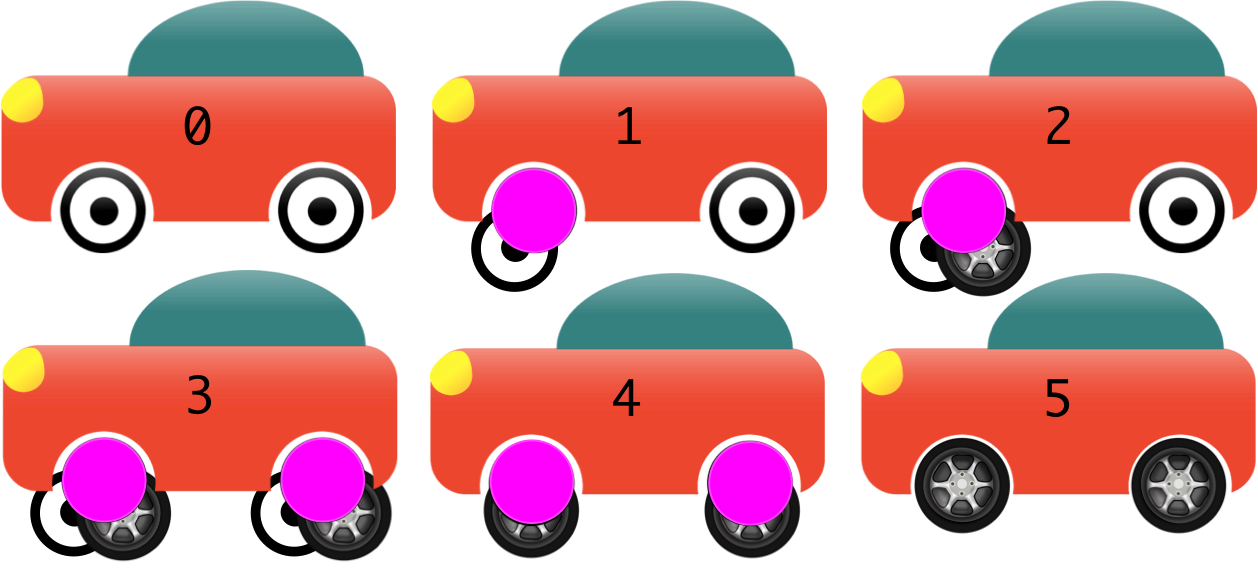
Note that this is by no means a wholly easier strategy of dealing with large features or changes, as using abstractions such as feature flags can introduce it's own complexities, as well as tech debt (needing to manage removing the abstraction diligently).
To read more on Branching by Abstraction (recommended) see these articles: